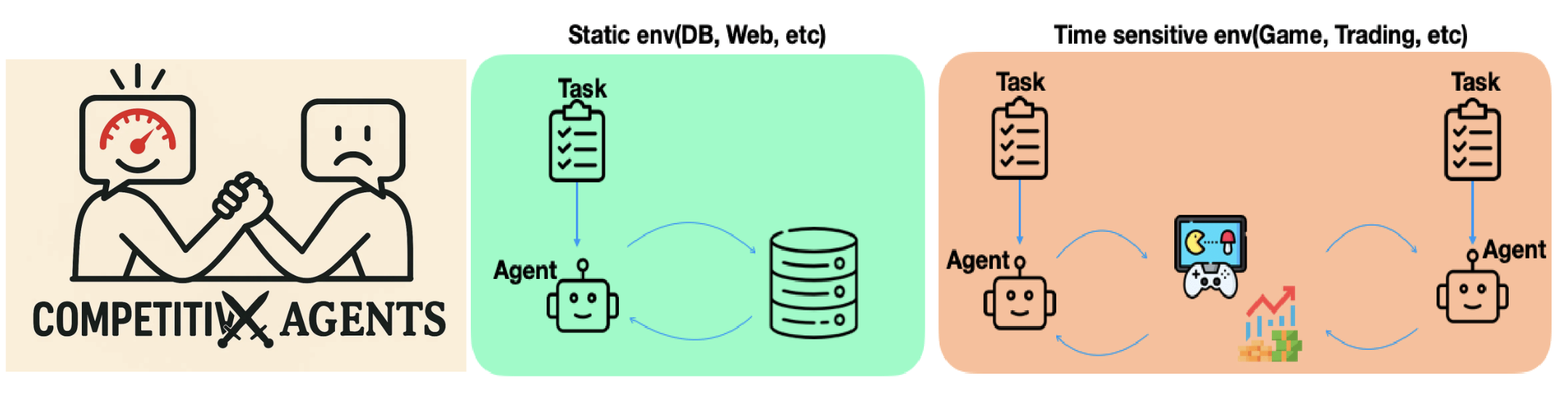
Large language models (LLMs) have shown remarkable performance across diverse reasoning and generation tasks, and are increasingly deployed as agents in dynamic environments such as code generation and recommendation systems. However, many real-world applications, such as high-frequency trading and real-time competitive gaming, require decisions under strict latency constraints, where faster responses directly translate into higher rewards. Despite the importance of this latency-quality trade-off, it remains underexplored in the context of LLM-based agents. In this work, we present the first systematic study of this trade-off in real-time decision-making tasks.
To support our investigation, we introduce two new benchmarks: HFTBench, a high-frequency trading simulation, and StreetFighter, a competitive gaming platform. We also designe a new mixed-precision inference framework, FPX, to enable fine-grained latency-quality trade-offs for LLM agents. Our analysis reveals that optimal latency-quality balance varies by task, and that sacrificing quality for lower latency can significantly enhance downstream performance.
LLM agents don't just need to think, they need to act fast. In real-time settings like high-frequency trading and competitive gaming, speed and quality go hand-in-hand.
We introduce two benchmarks that push LLMs into latency-critical roles: StreetFighter, a fast-paced fighting game, and HFTBench, a high-frequency trading simulator. Each task exposes different sensitivity to inference latency and output quality.
To address and evaluate these trade-offs, we propose FPX, an adaptive
mixed-precision inference framework that dynamically balances model size and bitwidth.
This allows fine-grained control over speed–quality balance, helping agents stay competitive under tight timing constraints.
Our findings reveal that faster isn't always worse, and smarter isn't always slower. This work opens the door to latency-aware design for future intelligent agents.
To evaluate LLM agents in real-time scenarios, we introduce two custom benchmarks:
These benchmarks capture different types of latency-sensitive decision-making and provide a testbed for evaluating the speed–quality trade-off in LLM-based agents.
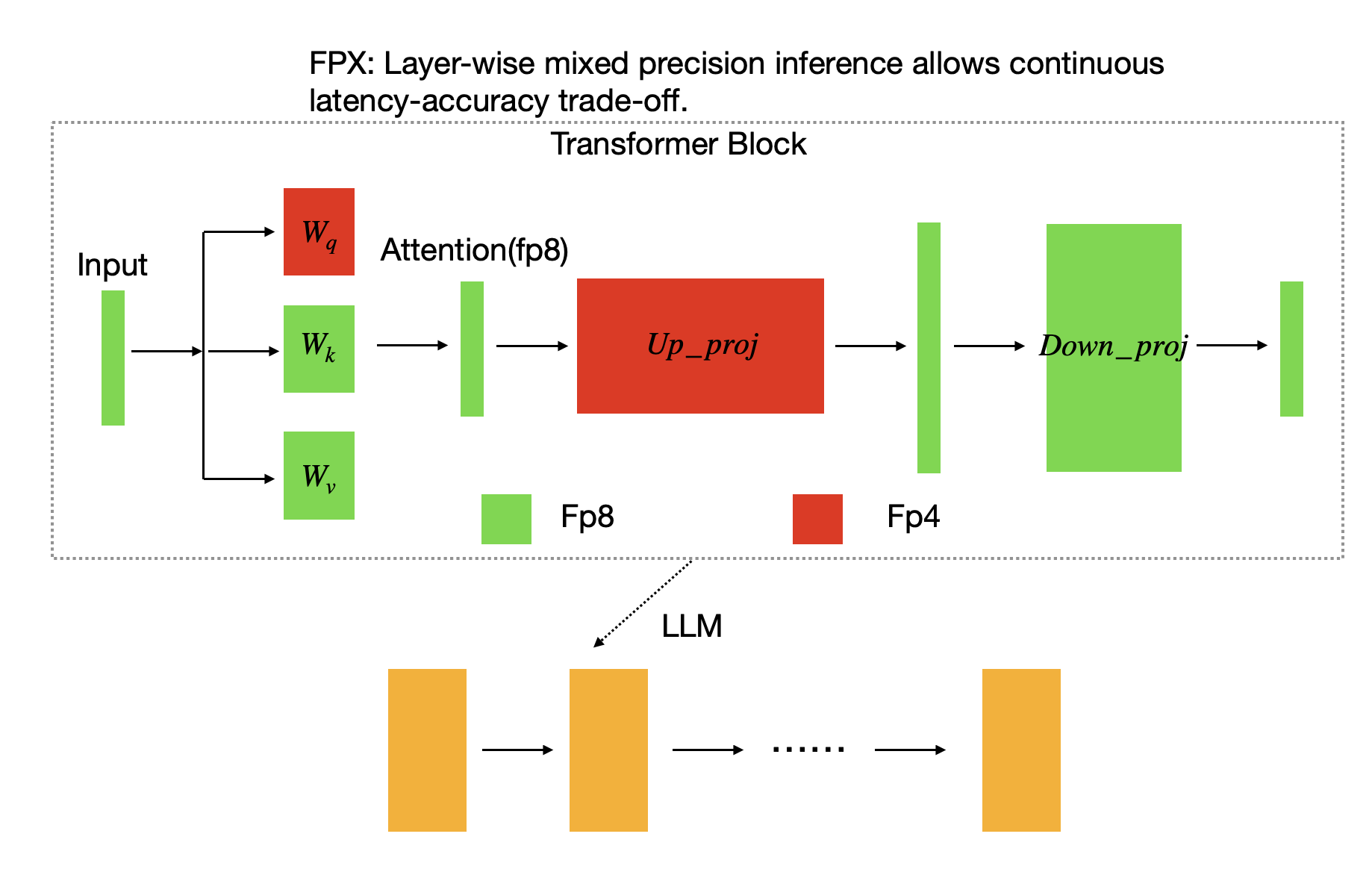
FPX is our adaptive mixed-precision inference algorithm that enables fine-grained latency–quality trade-offs for LLM agents. Instead of compressing entire models, FPX selectively applies FP4 only to layers that tolerate it best, while keeping FP8 for sensitive components.
Using a one-time offline calibration step, FPX measures the quantization error of each linear layer, then assigns lower precision to the most robust ones—achieving significant latency reduction with minimal accuracy loss.
This targeted approach enables LLM agents to respond faster in real-time environments like trading or gaming, without sacrificing decision quality.
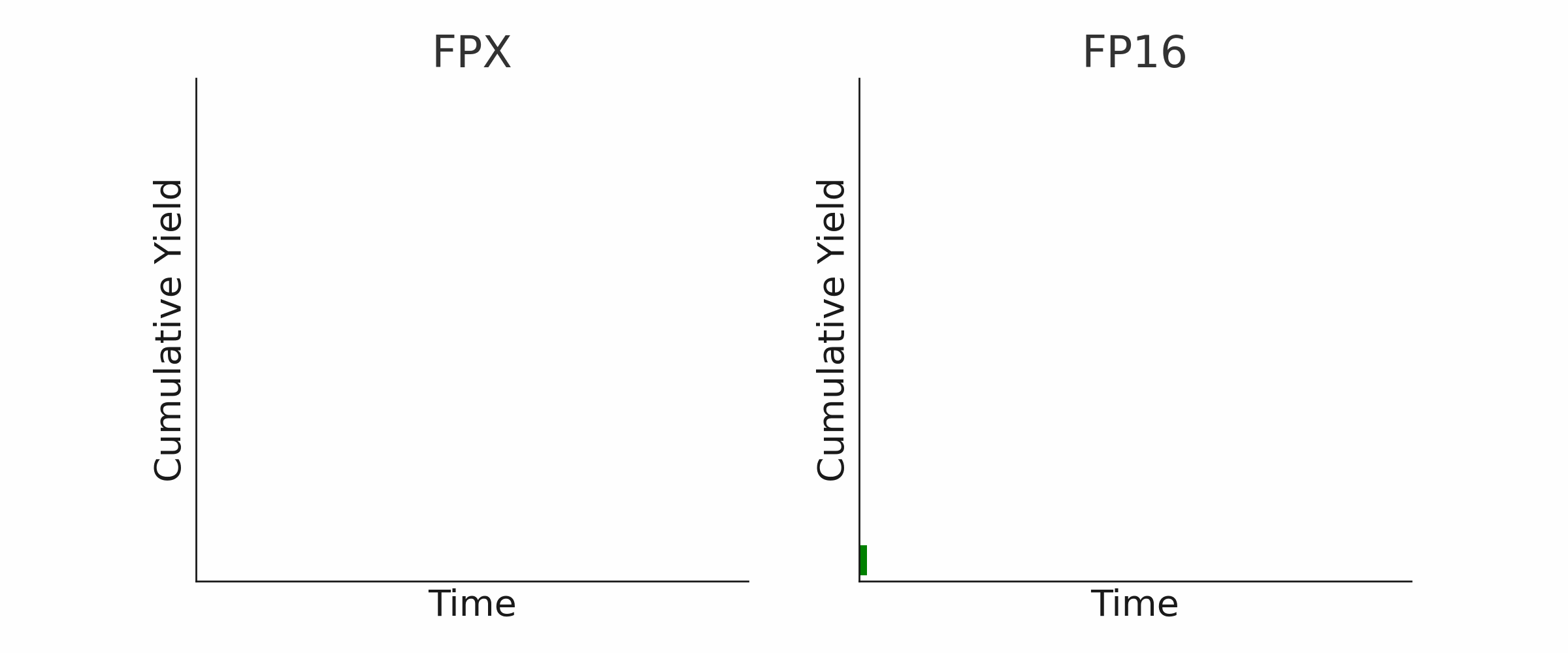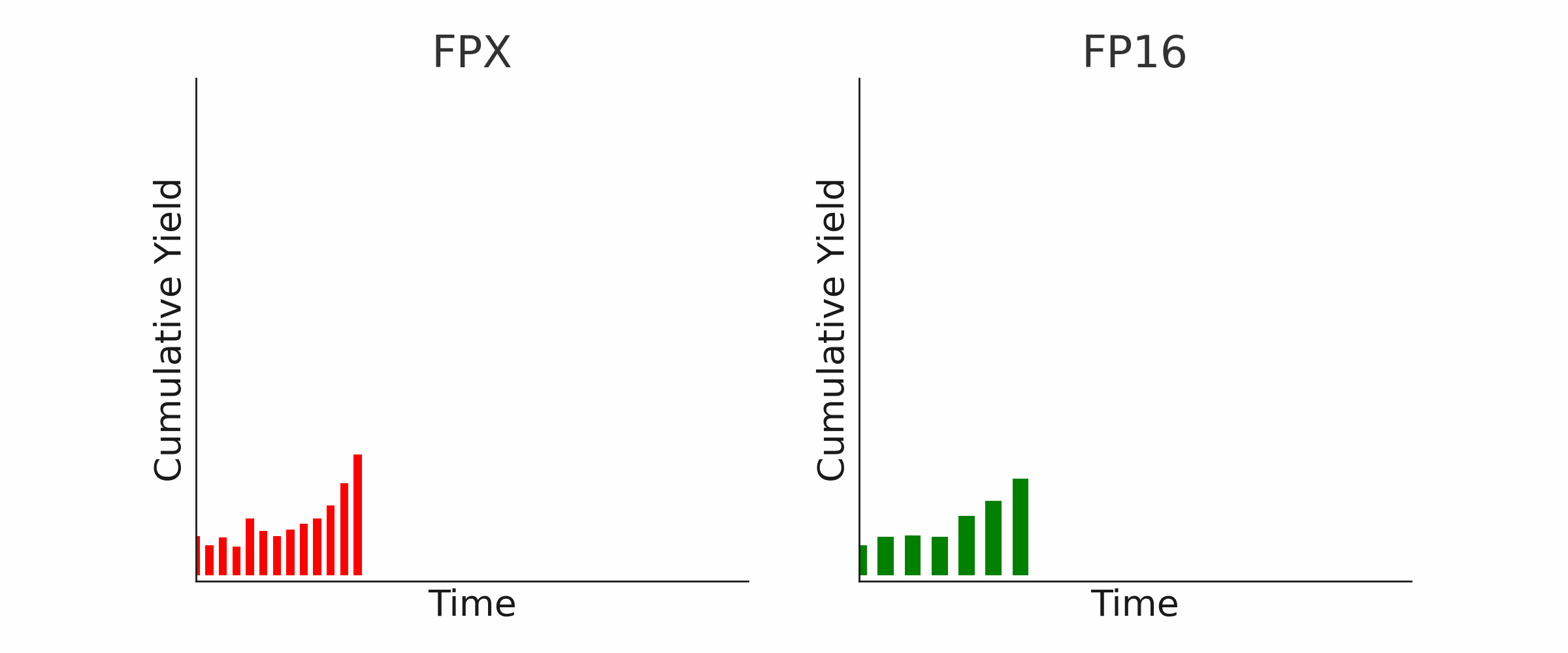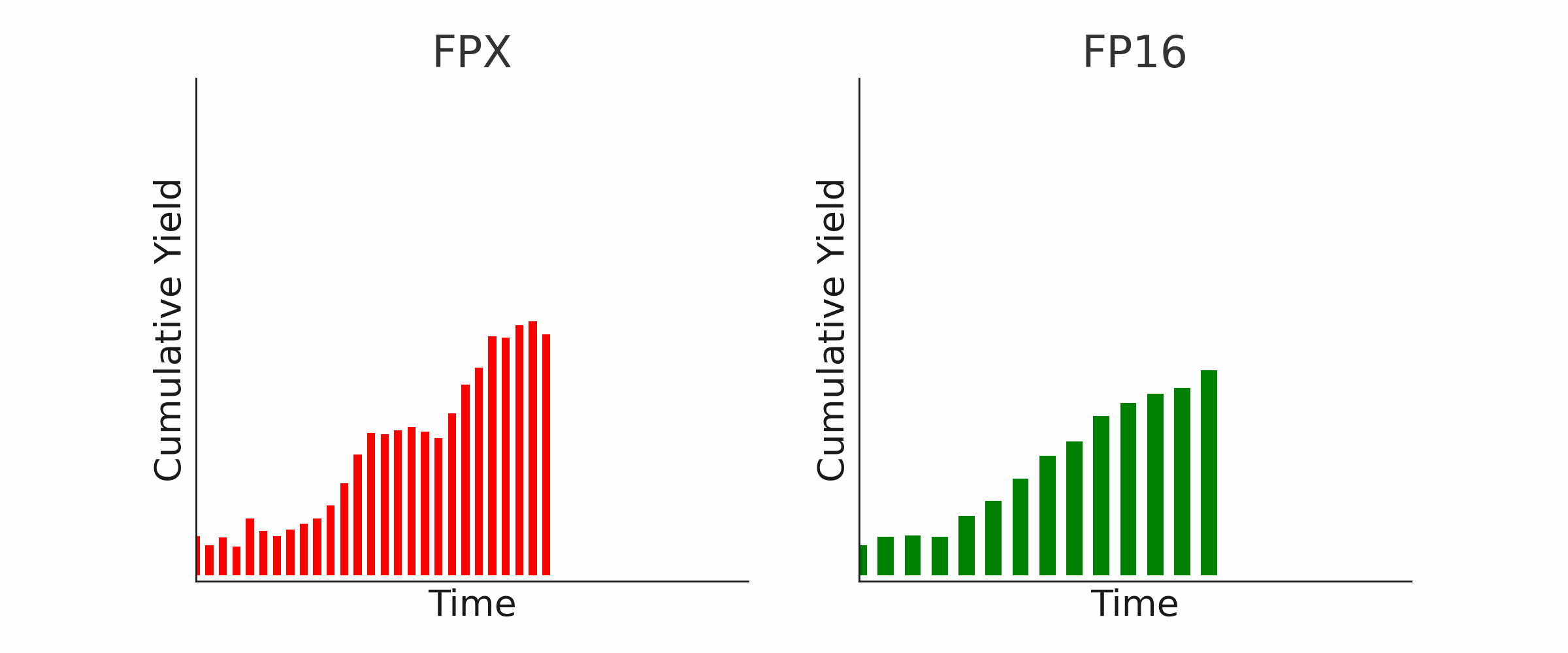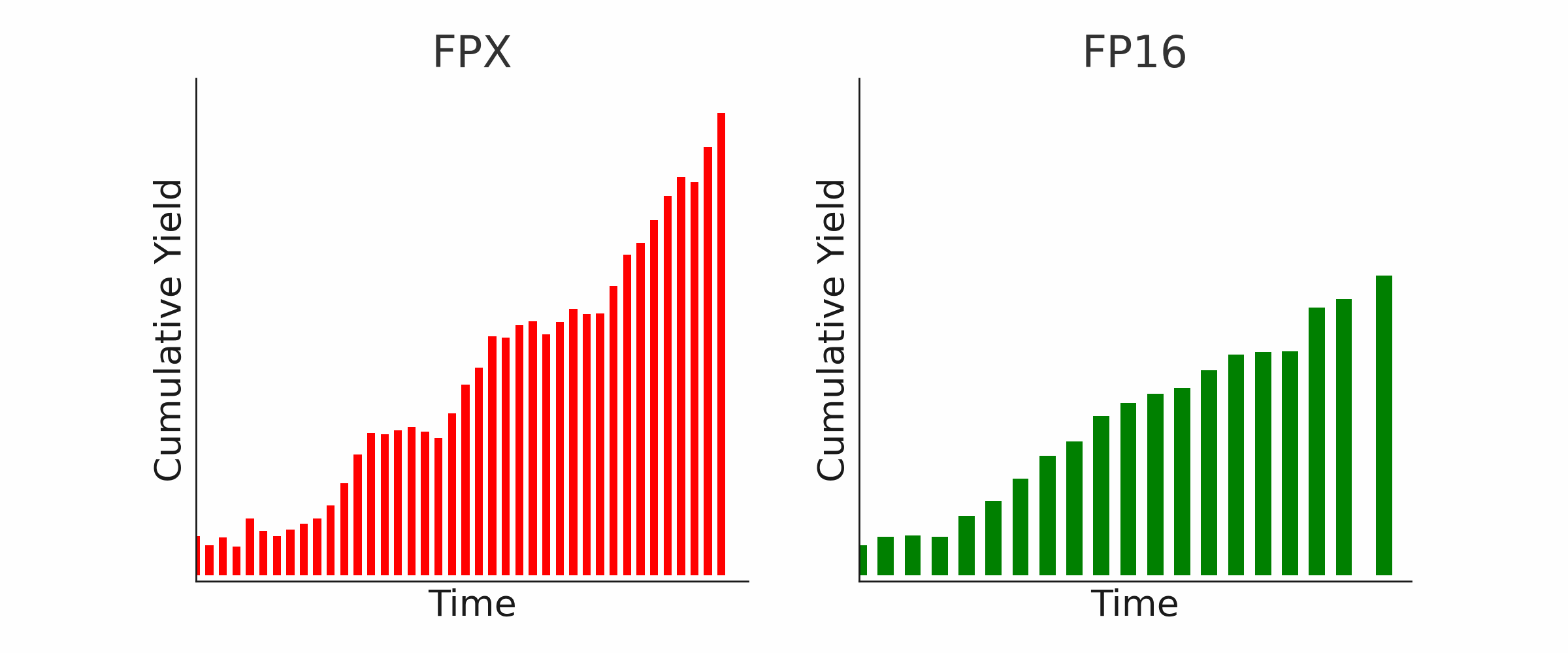
We evaluate our method on two latency-sensitive benchmarks: HFTBench for high-frequency trading and Street Fighter for real-time gaming. Our method dynamically adjusts model bitwidths to trade off latency and decision quality.
| Model Size | Bitwidth Avg | Latency (ms) ↓ | Daily Yield (%) ↑ |
|---|---|---|---|
| 14B (ours) | 7.2 | 713 | 26.52 |
| 14B | 8 | 801 | 23.14 |
| 14B | 16 | 1302 | 17.20 |
| 7B | 16 | 619 | -3.28 |
| 7B (ours) | 7.6 | 386 | -7.25 |
| 7B | 8 | 394 | -12.94 |
In HFTBench, larger models (e.g. 14B) consistently outperform smaller ones due to their superior ability to recognize profitable patterns. Speeding up weaker models like 7B does not help—poor decisions made faster often amplify losses. Our method improves 14B latency while retaining quality, achieving the best trade-off.
| Model Size | Bitwidth Avg | Latency (ms) ↓ | ELO Score ↑ |
|---|---|---|---|
| 3B (ours) | 6.8 | 195 | 5.99 |
| 7B (ours) | 7.2 | 354 | 2.33 |
| 3B | 8 | 222 | 2.19 |
| 3B | 16 | 349 | 0.25 |
| 7B | 8 | 394 | -0.44 |
| 1.5B | 8 | 142 | -1.25 |
In Street Fighter, faster models tend to win more, but only up to a point. Because the game enforces a fixed frame rate (~200ms per action), making decisions faster than this brings no benefit. Smaller models like 1.5B are fast but lack strategy, while our compressed 3B model achieves the best balance of speed and quality.
@misc{kang2025winfastloseslow,
title={Win Fast or Lose Slow: Balancing Speed and Accuracy in Latency-Sensitive Decisions of LLMs},
author={Hao Kang and Qingru Zhang and Han Cai and Weiyuan Xu and Tushar Krishna and Yilun Du and Tsachy Weissman},
year={2025},
eprint={2505.19481},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.19481},
}